





I. Glossaire▲
|
Cluster (ou ferme de serveurs) : |
Ensemble de serveurs (deux minimum) situés sur une même baie de disques pour assurer une continuité de service ou répartir le travail entre les machines (load-balancing). |
|
IIS : |
Internet Information Services, serveur Web de Microsoft. |
|
MSDCS : |
Acronyme pour Microsoft Distributed Cache Service. |
II. Introduction▲
Les avancées technologiques de ces dernières années (puissance de calcul, réseau, quantité de mémoire) ont engendré de fortes évolutions sur la conception et l'utilisation des applications Web ou desktop. Nos applications sont désormais pilotées par des données qui peuvent être hébergées en local, sur une base de données, un Web service. Ces données sont également accessibles en mode connecté ou déconnecté. De plus, elles doivent correspondre à un besoin métier et doivent donc être agrégées, recalculées, voire transformées.
Ces phases de récupération, agrégation, transformation peuvent engendrer des coûts importants sur :
- les accès réseau lors d'accès à système externe ;
- les serveurs Web ou bases de données accédées (charge CPU élevée due aux nombreux accès) ;
- la machine exécutant l'applicatif (retraitement des données à chaque exécution d'une méthode).
Afin d'apporter une réponse aux problématiques de performances et de temps de réponse des applications sollicitées par un grand nombre d'utilisateurs, il existe la possibilité de mettre en cache les données agrégées et/ou traitées.
Dans une première partie, je vous présenterai ce qu'est la notion de mise en cache. Une seconde partie exposera les différentes stratégies de cache existantes, dont l'usage d'un cache distribué au cœur de cette étude. Je conclurai en présentant les tests qui ont été effectués afin de comparer une stratégie de cache local et une de mise en cache distribué sur Microsoft Distributed Cache Service.
III. Le cache : une notion de performance▲
III-A. Qu'est-ce que le cache ?▲
La mise en cache consiste à stocker temporairement en mémoire une donnée fortement sollicitée par un ou plusieurs utilisateurs. Cet objet peut être une copie d'une donnée issue d'un service externe (exemple : base de données) ou d'une donnée agrégeant plusieurs sources de données et répondant à un besoin métier.
Un objet en cache doit répondre à plusieurs exigences :
- appartenir à un groupe de cache. Cette notion de groupe permet de structurer le cache ;
- posséder un identifiant unique afin de permettre un accès immédiat à celui-ci, de ne pas le modifier ou l'écraser lors de l'ajout d'un nouvel objet dans le cache. Cet identifiant est appelé « clé de cache ».
III-A-1. Un exemple concret▲
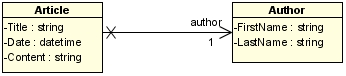
Prenons un site Web contenant une seule page. Cette page affiche une série d'articles. Un article contient un titre, un contenu (texte et images) et est créé par un auteur. Les données des articles sont contenues dans une base de données, les informations sur l'auteur sur un Web service distant. Pour afficher les articles, le site doit donc récupérer dans la base de données le contenu de ces derniers et sur le Web service les données liées à l'auteur.
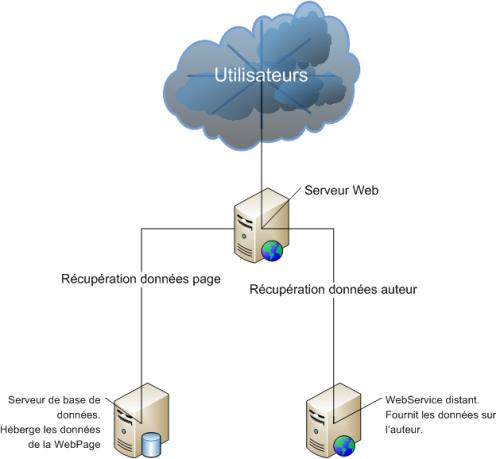
Ensuite, le site agrège les données dans la structure suivante :
Enfin, le serveur génère le rendu HTML qui sera affiché à l'utilisateur.
Afin d'optimiser le temps de réponse de notre site, nous pouvons mettre l'objet « Article » dans un cache. Le groupe de cache sera nommé « Articles ». L'unicité d'une page est définie par :
- la date ;
- le titre ;
- l'auteur.
Ainsi la clé de cache sera « $Date_$Heure_$Titre_$Auteur » où chaque variable sera remplacée par sa valeur.
III-B. Objet en cache : représentation, durée de vie et notifications▲
Un objet « caché » peut être représenté de différentes façons.
Imaginons une page Web en asp.net dont l'affichage ne change jamais. Plutôt que de laisser le serveur recalculer l'affichage de la page à chaque visite, il est possible de ne générer qu'une seule fois le rendu HTML, et de le stocker sur un cache disque. Ainsi, à chaque requête d'accès à la page, le serveur ira chercher la page rendue présente sur le disque plutôt que de recalculer le rendu.
Une autre possibilité est de mettre la page en mémoire et de s'assurer que la zone mémoire allouée ne sera jamais détruite. Cette tactique est conseillée pour stocker des objets qui seront peu ou pas recalculés (cas de l'exemple précédent) et est plus performante qu'un stockage sur disque.
III-B-1. Mise à jour d'une donnée▲
Une donnée peut avoir été mise à jour après la mise en cache. Cette mise à jour ne sera pas reportée sur le cache tant que l'applicatif n'aura pas interrogé la source de donnée originale. Or, si l'application trouve toujours l'objet dans le cache, elle ne se connectera pas à la source de données pour récupérer la nouvelle donnée.
Deux méthodes existent pour régler ce problème :
- l'expiration : consiste à appliquer une durée de vie aux objets dans le cache. Une fois le temps de vie de l'objet dépassé, le cache supprime l'objet ;
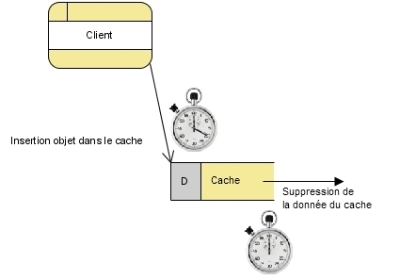
- les notifications : la source de données peut notifier à l'applicatif qu'un objet a été ajouté ou supprimé de sa collection, ou qu'il a été mis à jour et qu'il doit reporter la modification dans le cache (utilisable dans le cas de données locales, sur un réseau ou sur une base de données).

Ces mécanismes seront approfondis sur la partie étudiant le fonctionnement de Microsoft Distributed Cache Service.
Je viens donc de vous présenter les grands principes du cache. Dans la partie suivante, j'exposerai deux tactiques de mises en cache : local ou sur service de cache distribué. Qu'est-ce qui les différencie ? Quels sont les avantages de l'une face à l'autre ? Voilà les thèmes de la section qui suit.
III-C. Cache Local▲
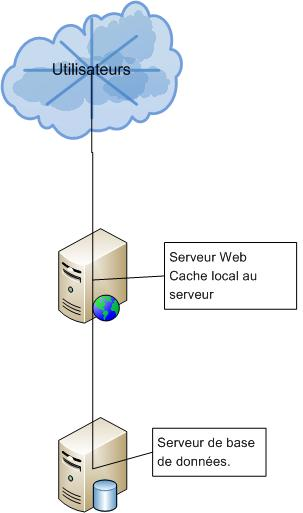
Le cache local contient les données mises dans le cache par un applicatif. Mais que se passe-t-il lorsque cet applicatif (Web par exemple) est basé sur une architecture distribuée ?
Un site Internet à forte audience est composé de plusieurs serveurs Web. Chaque serveur contient le site Internet et est donc consommateur d'un cache qui lui est propre. L'usage d'un cache local est alors assez contraignant. En effet, chaque serveur doit requêter au moins une fois la source de donnée pour avoir son objet dans le cache. Deux problématiques vont se poser :
- on possède n copies du cache, où n est le nombre de serveurs ;
- prenons deux serveurs, à un instant T le serveur 1 requête la source de données et met son objet en cache. À l'instant T+1, la donnée est mise à jour dans la source. À l'instant T+2 le serveur 2 requête la source de données : le cache du serveur 2 contient une version de la donnée différente du serveur 1. Ceci peut mener à une incohérence sur le contenu du site Internet.
En exploitant un cache local, il n'existe aucune solution pour avoir une version commune du cache. Pour le second problème, une alternative consiste à copier la donnée présente dans le cache du serveur 1 vers celui du serveur 2.
Exemple : le serveur 1 requête la source de données et positionne le résultat dans son cache. Dans ce même temps, il transmet l'objet à tous les autres serveurs qui l'inséreront à leur tour dans leur cache. De même lors de la mise à jour ou suppression d'une donnée.
On a donc n caches dupliqués et contenant exactement les mêmes données. Toutefois, cette solution est assez peu convaincante. Cette duplication de données charge la mémoire physique des serveurs et il est important de savoir gérer les accès en concurrence aux objets. Si le serveur 2 ajoute en même temps que le serveur 1 un objet x, que se passe-t-il ? Cela met en évidence les limites du cache local dans le cadre d'une architecture distribuée.
Comme cela sera démontré plus tard, le cache local répond aux besoins de performances, mais montre ses limites lorsque l'on se situe dans une architecture répartie. Toutefois il existe la possibilité de mettre en place un ou plusieurs serveurs de cache qui permet d'avoir un seul et unique cache distribué entre ces serveurs. Dans la partie suivante, je vous présenterai l'infrastructure applicative et matérielle d'un cache distribué en m'appuyant sur le sujet principal de cette étude : Microsoft Distributed Cache Service.
IV. Microsoft Distributed Cache Service▲
Anciennement appelé « Velocity », MSDCS est délivré avec l'ensemble applicatif nommé « Microsoft Server 2008 AppFabric». Son but est de permettre la mise en place d'un service de cache distribué répondant à des besoins croissants en termes de performances et de haute disponibilité des architectures réparties. Cette partie présentera certaines fonctionnalités délivrées dans cette première version de MSDCS.
IV-A. Fonctionnalités▲
Microsoft Distributed Cache Service offre les fonctionnalités répondant aux besoins d'un service de cache distribué et qui sont les suivantes :
- support de la taille de l'entreprise : support d'un cluster de quelques serveurs à plus d'une centaine ;
- redimensionnement dynamique du cluster : possibilité d'ajouter ou supprimer des serveurs (ou nœuds) sans couper le service ;
- support de deux configurations de déploiement : service réseau ou embarqué dans une application ;
- support des configurations de cache fréquentes ;
- Load-Balancing automatique : le service distribuera automatiquement le travail entre les différentes machines du cluster afin d'augmenter la qualité de service ;
- haute disponibilité des données en permettant la réplication de données dans le cache ;
- architecture de type « Cache Explicite » : l'applicatif détermine quels objets mettre en cache, il n'existe pas de possibilité de synchronisation entre le cache et une source de données ;
- support de plusieurs langages clients (PHP, C#, etc.) ;
- support des sessions ASP.NET.
Dans la suite de cette étude, je m'intéresserai plus particulièrement à l'architecture du service de cache distribué, sa gestion, les configurations de cache (répliqué, partitionné) ainsi que les processus maintenant la cohérence du cache.
IV-B. Infrastructure d'un cache distribué▲
Le but d'un cache distribué est de fournir une vue unifiée du cache. Le ou les clients doivent percevoir le cache comme un unique cache local.
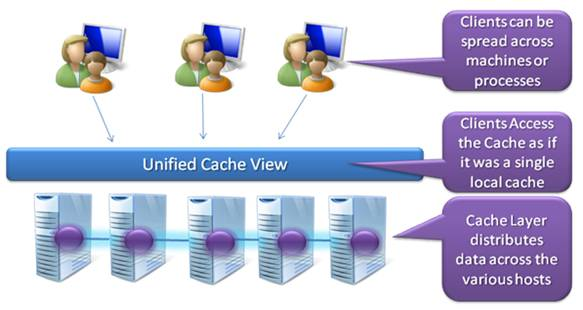
L'infrastructure peut donc être définie de la façon suivante :
- les utilisateurs accèdent à une ferme de serveur Web ;
- le serveur Web récupère ses données soit dans le service de cache s'il les contient, soit en base de données.
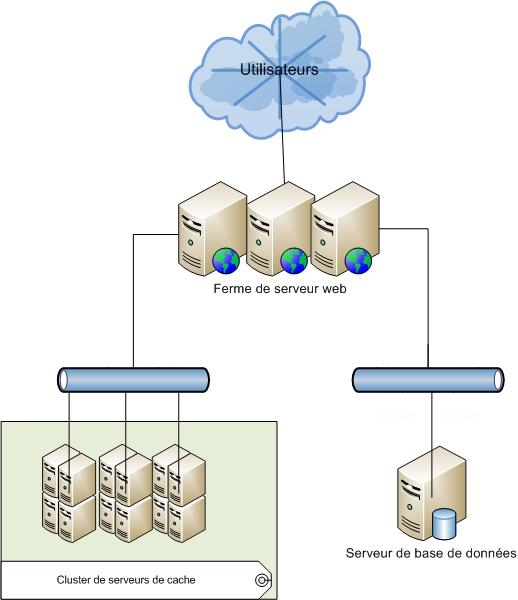
Chaque machine d'un cluster est appelée « nœud ». Il existe deux types de nœuds : les primaires et les secondaires.
Les nœuds primaires sont les machines requêtées par les applicatifs pour insérer, modifier ou supprimer un objet. Les nœuds secondaires sont les serveurs définis pour contenir une copie de sauvegardes des objets présents dans le cache. Plus précisément, ils servent à répliquer les données d'une région d'un cache nommé (voir partie « Le cache vu comme une hiérarchie »). En cas de panne d'un nœud primaire, le nœud secondaire sera utilisé pour restaurer dans le cache les données perdues.
IV-C. Le cache vu comme une hiérarchie▲
IV-C-1. Le couple machine - hôte▲
Microsoft Distributed Cache Service définit une hiérarchie dans le cache. Le premier niveau de hiérarchie est la machine. Une machine peut contenir un ou plusieurs hôtes de cache. L'ensemble machine et hôtes définit le cluster.
IV-C-2. Cache nommé▲
Le cache se doit d'être organisé afin d'augmenter les performances en lecture/écriture. Ainsi, chaque objet doit être contenu dans un « cache nommé ». Exemple : les produits d'un site d'e-commerce seront stockés dans le cache nommé « ProductCatalog ». Chaque nœud du cluster peut contenir un ou plusieurs caches nommés. De même, un cache nommé ne peut être défini que sur un ensemble de nœuds du cluster.
IV-C-3. Les régions▲
Un cache nommé est composé de régions. Une région représente un groupe logique et est analogue à une table d'une base de données. Par exemple :
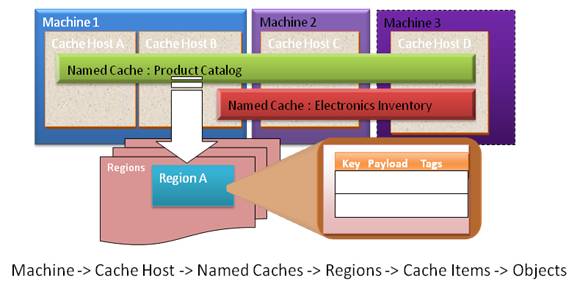
Un objet peut être explicitement inséré dans une région précise. Dans le cas où aucune région n'est définie, le système créera de lui-même les groupes logiques.
IV-C-4. Éléments de cache▲
Une région se compose d'éléments. L'élément est l'entité de plus bas niveau dans le cache. En plus de contenir la clé d'un objet et son contenu, il contient aussi des informations sur cet objet telles que :
- sa date de création ;
- sa durée de vie dans le cache ;
- sa version (i.e. le numéro de version s'incrémente à chaque mise à jour de l'objet) ;
- et d'autres informations statistiques.
Chaque élément est garanti de résider sur un seul nœud du cluster et est l'unité logique utilisée pour la réplication ou la restauration de données.
Enfin, un objet contenu dans un élément est toujours stocké sous forme « sérialisée ».
IV-D. Types de caches▲
MSDCS permet l'usage des configurations fréquentes de cache : partitionné, dupliqué, ou local.
IV-D-1. Partitionné▲
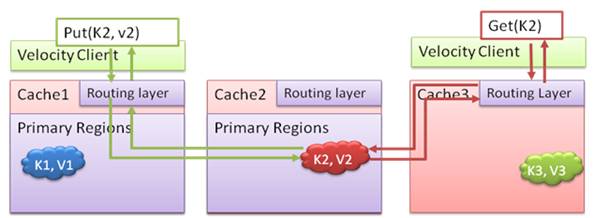
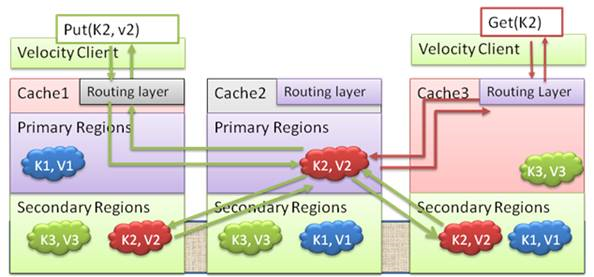
Tel que son nom l'indique, le cache partitionné permet de répartir les objets dans tout le cluster. Pour cela, il découpe les régions d'un cache nommé et les positionne sur tous les nœuds où le cache nommé est défini. Cette tactique permet de combiner la mémoire vive disponible sur tous les nœuds afin d'augmenter la quantité de données pouvant être mises en cache. Les accès en écriture et lecture seront dirigés sur la région qui contient la copie principale de l'objet.
Le schéma ci-dessous illustre le fonctionnement des opérations Put et Get dans un cache partitionné. Dans le cas où le client exécute une opération Put sur le Cache 1 pour insérer une valeur « v2 » de clé « K2 », la couche de routage du Cache 1 détermine que la clé « K2 » appartient au Cache 2 et redirige la requête vers le serveur hôte de ce cache. De la même façon, les requêtes Get pour la même clé seront aussi dirigées vers le Cache 2.
Il est possible d'ajouter des nœuds secondaires afin d'augmenter la disponibilité et la sécurité d'un cache partitionné. Pour rappel, l'ajout de nœuds secondaires sur des régions d'un cache nommé permet de dupliquer les données contenues dans une région et de les restaurer en cas de panne d'un nœud primaire.
L'exemple suivant montre le fonctionnement de l'ajout et la récupération d'un objet dans un cache partitionné configuré avec deux caches secondaires. Le client envoie une requête d'insertion la valeur « v2 » de clé « K2 » dans le Cache 1. La couche de routage du Cache 1 détermine que la clé « K2 » appartient au Cache 2 et effectue le routage. Le Cache 2 ajoute l'élément et envoie une copie de la donnée aux deux autres nœuds secondaires. Dès réception d'un accusé réception des nœuds secondaires, il prévient le Cache 1 que l'opération a réussi. Le Cache 1 relaye l'info au client. Il n'y a aucun changement de comportement dans le cas d'une opération de lecture d'un objet.
IV-D-2. Répliqué▲
Ce type de cache permet la copie de tous les éléments dans les nœuds du cache nommé.
L'exemple suivant illustre l'usage d'un cache répliqué. Lorsque le client insère un objet de clé « K2 » et de valeur « v2 » dans le Cache 1 qui redirige la requête vers le nœud primaire gérant cette région. Le Cache2 effectue une écriture locale et envoie l'accusé réception à Cache 1 qui notifie au client que l'opération s'est bien déroulée. Pendant ce temps, le Cache 2 propage de façon asynchrone le changement sur tous les hôtes du cache nommé.Une requête Get sur un cache répliqué est toujours gérée localement.
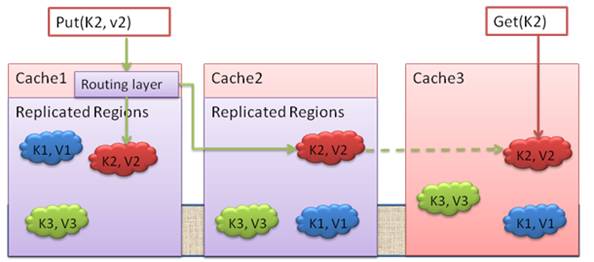
Cette configuration de cache est appropriée pour les données souvent accédées en lecture seule et changeant peu. Un exemple : les villes d'un pays. Cet usage permet notamment d'accélérer les requêtes d'obtention d'objets puisque le service n'aura pas à chercher l'objet dans un nœud particulier du cluster.
IV-D-3. Local▲
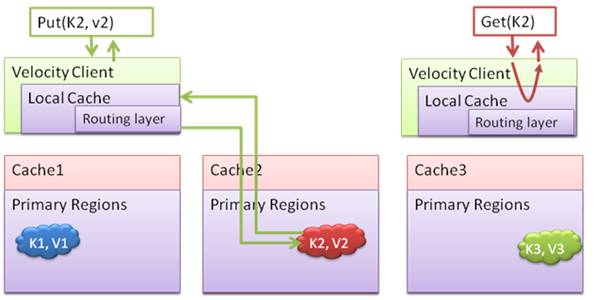
Dans le cas où un client accède très fréquemment à une donnée, il peut être utile de maintenir un cache local au niveau de l'applicatif. Dans ce cas, c'est la référence de l'objet qui est stockée dans le cache local (et non sous forme sérialisée). Cela permet d'économiser les temps de sérialisation et désérialisation des objets, de diminuer la charge réseau et des serveurs de cache primaire. Il en résulte une nette amélioration des performances.
L'exemple suivant montre l'usage d'un cache local. Lorsque l'applicatif insère un élément de valeur « v2 » et de clé « K2 » sans le cache, l'opération est effectuée dans le cache local puis propagée sur le nœud de cache primaire. Lors d'un accès en lecture, seul le cache local sera utilisé.
IV-E. Maintien de la cohérence des données et du cache▲
Le cache se doit d'être fiable. Il existe donc plusieurs techniques pour maintenir la cohérence du cache face aux sources de données originales.
IV-E-1. Expiration et Éviction▲
Microsoft Distributed Cache Service garantit la validité des données en supportant les techniques d'expiration et d'éviction des données.
IV-E-1-a. Expiration▲
Quand un objet est ajouté dans le cache, il est possible de lui attribuer une durée de vie. Une fois expirée, la donnée est retirée du cache.
IV-E-1-b. Éviction▲
L'éviction consiste à appliquer un marquage sur les objets mis en cache. Ce marquage indique la date d'accès à l'objet et permet d'appliquer un algorithme de type « Dernier objet utilisé » pour évincer l'objet du cache.
IV-E-2. Notifications▲
Qui dit « architecture distribuée » dit « grand nombre de clients » qui potentiellement travaillent avec les mêmes données. Afin d'avertir un client d'un changement effectué dans le cache par un autre client, il est possible de définir des notifications sur une région ou un élément de cache. À chaque insertion, mise à jour, suppression d'un objet dans le cache, une notification est envoyée à tous les clients.
Au travers de cette présentation de Microsoft Distributed Cache Service, je vous ai exposé les principes du cache distribué. Dans la dernière partie de cette étude, je vais vous présenter les tests effectués avec MSDCS afin de déterminer quels sont les gains en termes de performances sur une application Web.
V. Tests▲
Le but de ces tests est de déterminer quels sont les gains ou pertes en termes de performances lorsque l'on utilise Microsoft Distributed Cache Service, ou un cache local, ou aucun cache. Je commencerai donc par vous présenter l'infrastructure mise en place pour effectuer ces tests, les données exploitées et les développements effectués. Après avoir exposé le protocole des tests, je conclurai avec les résultats obtenus.
V-A. Infrastructure▲
L'infrastructure de tests est la suivante :
- un serveur Web IIS7 sous Windows Server 2008 R2 contenant un site Web développé sous .NET Framework 4.0 ;
-
deux serveurs de cache distribués sous Windows Server 2008 R2 et Microsoft Distributed Cache Service :
- le cluster ne contient qu'un seul cache nommé,
- les deux serveurs sont configurés en tant que nœuds primaires,
- la durée de vie d'un objet dans le cache est fixée à 4 h,
- aucun système de notification sur les objets n'a été mis en place,
- aucune région n'a été explicitement créée ;
- un serveur de base de données sous SQL Server 2008 Service Pack 1 ;
- tous les serveurs sont situés dans un même réseau interne.
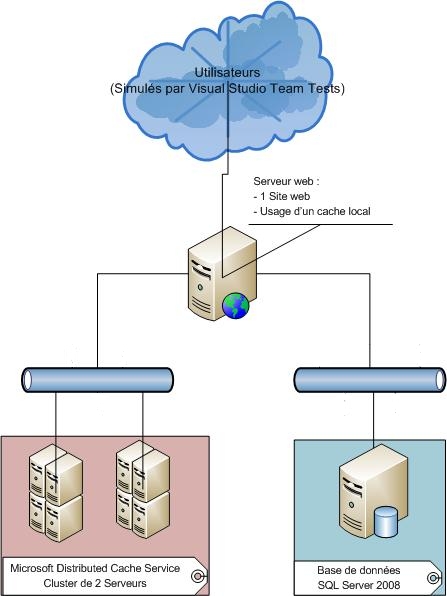
Le serveur Web et les serveurs de cache sont tous équipés d'un processeur à 4 cœurs, 4 Go de ram. Le serveur SQL Server 2008 s'exécute sur une machine possédant 16 cœurs d'exécution et 32 Go de ram.
V-B. Développements▲
L'applicatif de test développé consiste en un site Internet contenant trois pages. Ces pages affichent les informations sur un client (nom, prénom, date de naissance, adresses, etc.).
La première étape fut de créer une architecture basique :
- un service « Entity » qui accède aux données présentes en base de données ;
- un service métier (« Category ») qui récupère les données issues du service « Entity » et les fournit à la page Web ;
- deux gestionnaires de cache : l'un exploite un cache local basé sur l'implémentation fournie dans le .NET Framework (System.Web.Caching) et l'autre utilise MSDCS.
Le diagramme de classe suivant illustre cette architecture.
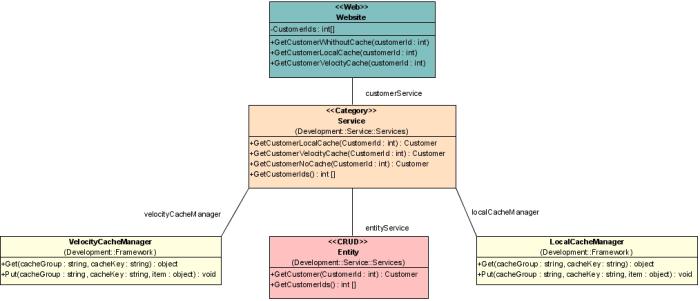
Le service métier expose trois méthodes qui prennent toutes en paramètre l'identifiant en base de données du client.
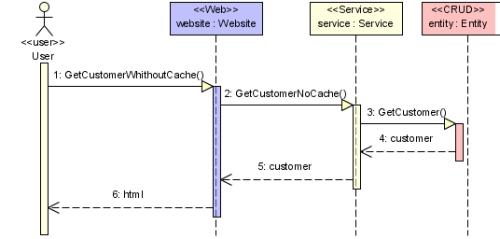
La première méthode, nommée GetCustomerWithoutCache permet d'aller chercher les données d'un client directement en base de données. Une page du site Internet appellera cette méthode. Le diagramme de séquence ci-dessous décrit l'obtention d'un client en base.
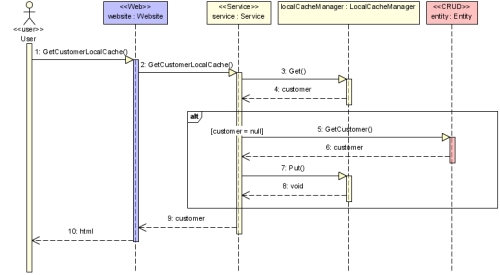
Une seconde méthode permet d'exploiter le cache local au serveur Web. Lors de l'appel à cette méthode, le service consommera le localCacheManager. Si le client existe dans le cache, le service retournera cette donnée. Dans le cas contraire, il interrogera la base de données via le service de category, insérera la donnée dans le cache puis la retournera à la page Web chargée de l'affichage. Le diagramme de séquence suivant illustre cette exécution.
Dans la même idée, la troisième méthode exploitera le cache distribué.
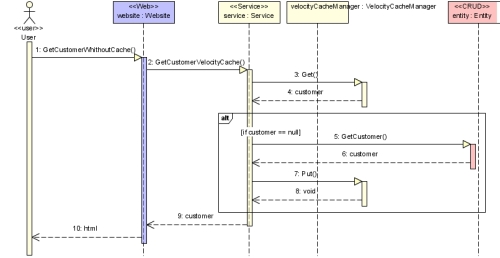
Une page du site n'appelle qu'une seule méthode du service métier.
V-C. Données▲
La base de données est constituée de deux tables :
- [dbo].[Customer] : contient l'ensemble des données liées à un client ;
- [dbo].[Address] : contient les adresses des clients.
Une fois transposée au monde .NET, on obtient l'objet Customer suivant :
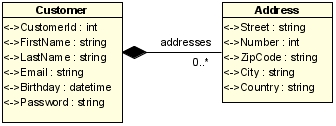
Les données insérées en base respectent les contraintes suivantes : une adresse ne peut appartenir qu'à un seul client, un client possède une à trois adresses. De plus, pour simplifier les calculs sur la taille des données, les règles suivantes ont été fixées :
- le prénom et nom d'un client sont fixés à 30 caractères ;
- l'email se compose de 100 caractères ;
- le mot de passe est de 255 caractères ;
- une rue est définie sur 255 caractères ;
- un pays et une ville sur 20 caractères.
La base de données contient 150 000 clients et 300 000 adresses.
Ainsi, l'empreinte mémoire d'un client est de :
- 455 octets pour le prénom, nom, email, mot de passe (1 caractère = 1 octet) ;
- 4 octets pour son identifiant ;
- 8 octets pour sa date de naissance ;
-
en moyenne deux adresses, donc :
- 2 * 295 octets pour les rues, villes, pays.
- 2 * 4 octets pour les numéros.
- Total = 598 octets ;
- Total : 1065 octets.
La taille totale des données est donc de : 159,75 Mo.
V-D. Protocole▲
Les tests ont été effectués à partir de la plateforme Visual Studio Team Suite Test Edition 2008. Trois tests ont été effectués :
- appels à la page utilisant que les données présentes en base de données ;
- appels à la page exploitant un cache local au serveur Web ;
- appels à la page exploitant le cache distribué.
Les variables analysées ont été :
- le nombre d'appels effectués par seconde ;
- le temps de réponse de la page appelée à chaque exécution ;
- la charge processeur du serveur de base de données.
La durée de chaque test est de 1 h 30. Les agents de tests de Visual Studio simulaient la présence de 450 utilisateurs sur le site, et cela pour toute la durée du test. Chaque appel à une page provoque la récupération d'un « Customer » à partir de son identifiant « CustomerId » (identifiant en base de données). Cet identifiant est aléatoire et choisi dans la liste des identifiants de « Customer » disponibles en base de données, ce qui garantit l'existence de l'objet recherché.
Pour les tests exploitant un cache, le cache a été vidé avant le début de chaque test. Afin de ne pas pénaliser les performances des machines, les mises à jour automatiques de Windows, l'Antivirus, ainsi que les processus de monitoring ont été désactivés.
V-E. Résultats et Conclusion▲
|
Sans cache |
Avec cache local |
Avec cache distribué |
|
|
Nombre total de requêtes |
384 619 |
3 014 454 |
2 350 919 |
|
Moyenne Nb Tests/s |
35.5 |
278.77 |
217.39 |
|
Moyenne Temps de réponse |
5.00s |
0.61s |
1.06s |
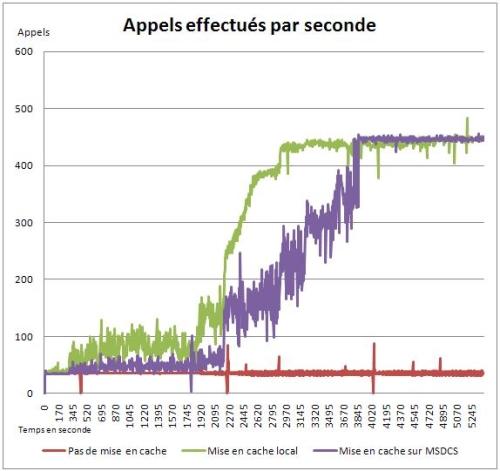
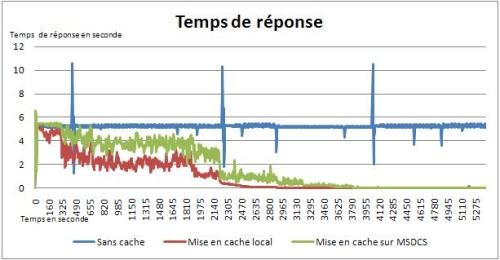
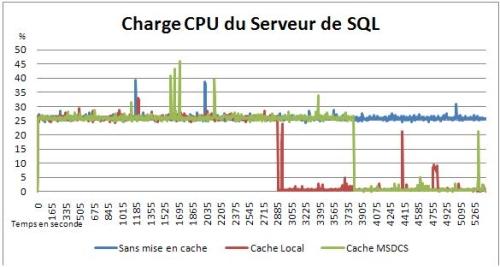
Ces résultats démontrent l'intérêt de mettre en place un système de cache. Les graphiques 19 et 20 prouvent que la mise en place d'un cache permet d'augmenter progressivement les performances d'accès aux données et de réduire le temps de réponse du site Web. De même, le graphique 21 atteste que la charge CPU du Server SQL se trouve réduite, jusqu'à être proche de nulle, dès qu'il y a un nombre suffisamment important de données dans le cache. À noter les quelques « pics » présents à temps régulier, cela est dû à des processus de synchronisation tournant sur le serveur SQL et sont externes à la procédure de tests.
On peut observer que la mise en cache distribué est plus progressive que la mise en cache local. Cela est dû au coût de sérialisation et désérialisation des données à mettre dans le cache distribué, opération qui n'a pas lieu dans le cas du cache local. En revanche, le fait que les deux systèmes de cache finissent par obtenir le même niveau de performance est plus contestable. Les accès réseau au serveur à Microsoft Distributed Cache Service devraient avoir un impact sur les performances. Mais cela s'explique par le fait que mes machines de tests sont en réalité des machines virtuelles hébergées sur la même machine physique. Donc le coût des accès réseau est quasi nul.
Pour conclure, que se passerait-il en cas de redémarrage de IIS7 sur notre serveur Web ? Le cache local serait vidé, et tout le processus de mise en cache serait à refaire. En exploitant le cache distribué, le site exploiterait directement les données issues du cache et retrouverait immédiatement sa disponibilité et ses performances d'avant coupure. Cela met donc en évidence la robustesse offerte par le cache distribué.
VI. Conclusion▲
Au cours de cette étude, j'ai présenté ce qu'est le cache et son intérêt. S'en est suivi une introduction à Microsoft Distributed Cache Service et les tests de cette plateforme prouvant son intérêt dans le cadre d'une architecture distribuée. Cette analyse s'est concentrée sur les concepts de base du cache réparti. Les paramètres tels que les accès en concurrence, la charge du réseau, l'équilibre de la répartition des données dans le cache, etc. n'ont pas été évoqués.
Une suite de cette étude se concentrera sur l'installation de MDCS, son administration et l'usage des API de cache.
Bibliographie▲
- Mic091 - Microsoft. (2009, juin). Build Better Data-Driven Apps With Distributed Caching. Novembre 2009, MSDN Magazine: http://msdn.microsoft.com/en-us/magazine/dd861287.aspx
- Mic092 - Microsoft. (2009, décembre). Documentation sur Windows Server AppFabric. Janvier 2010, MSDN Library: http://msdn.microsoft.com/en-us/library/aa139632.aspx
- Mic094 - Microsoft. (2009, novembre). Introduction to Caching with Windows Server AppFabric (Beta 1). Janvier 2010, MSDN Library: http://msdn.microsoft.com/en-us/library/cc645013.aspx
- Mic095 - Microsoft. (2009, décembre). Windows Server AppFabric. Janvier 2010, Site Officiel: http://msdn.microsoft.com/fr-fr/windowsserver/ee695849(en-us).aspx
Remerciements▲
Je remercie toute l'équipe DotNet, plus particulièrement Nicopyright(c) et Jacques_jean, pour leur relecture de ce document.
Contact▲
Si vous constatez une erreur dans cet article, ou pour toutes informations, n'hésitez pas à me contacter par le forum.